Sondes HTTP : superviser un intranet, un site public ou une API et lever des incidents
Un des besoins de nos clients est simple : détecter rapidement un services KO (intranet, site public, endpoint API). Cela peut passer par de la détection simple ("est-ce que le site web retourne bien du contenu avec un code de retour 200 ?") ou par de la détection avancée. Pour ça, nous avons mis en place des sondes HTTP configurables, où l'on peut spécifier :
- la méthode HTTP (
GET,POST,PUT,PATCH,DELETE,HEAD,OPTIONS) - le code de retour attendu (
200,201, ...) - des en-têtes personnalisés (exemple : une clé d'API, un token Bearer, ...)
- une payload
- une logique de statut vert/jaune/rouge
- la configuration de levée d'incidents par statut
Le but n'est pas simplement d'afficher un point rouge, mais de lever le bon incident, avec le bon niveau d'information (priorité, tags, données d'incident).
Ce que couvre concrètement une sonde
Chaque sonde repose sur quelques champs de base :
- Un nom : pour identifier clairement ce qui est contrôlé
- Une URL : la cible à vérifier
- Une fréquence : 5, 15, 30 minutes ou 1 heure (selon le plan souscrit)
- Un nombre d'essais maximum : nombre d'essais consécutifs (utilisés pour évaluer le statut vert/jaune/rouge)
Cette base permet de monitorer aussi bien :
- un intranet d'entreprise,
- qu'un site internet public,
- ou qu'une API interne/externe
HTTP avancé : pas seulement un GET
Le moteur de sonde supporte les verbes suivants :
GETPOSTPUTPATCHDELETEHEADOPTIONS
Vous avez aussi possibilité de renseigner une payload (un corps de requête). Cela permet de vérifier des cas réels :
- un endpoint de santé (health) classique en GET
- ou un endpoint qui répond correctement seulement avec une payload précise
En-têtes personnalisés
On peut ajouter des headers libres, par exemple :
Authorization: Bearer <token>X-API-Key: <api-key>X-Tenant: <tenant-id>
Utile pour monitorer des endpoints non publics ou multi-tenant.
Le cas des endpoints non publics (intranet privé, APIs internes, ...)
Vous souhaitez aussi contrôler des sites web privés et des APIs ou outils internes (non exposés publiquement) ? Les sondes Astry disposent d'un jeu d'IPs sources fixes (visibles directement sur le panneau de documentation de l'outil Sondes sur votre compte), vous avez donc possibilité d'autoriser les IPs d'Astry à venir interroger vos services pour garantir le bon fonctionnement des contrôles sans exposer vos services à tous.
Critère de succès HTTP
Sur chaque sonde on définit un code de retour attendu.
Par exemple :
200sur un endpoint de santé (c'est la valeur par défaut)- ou bien
204sur une route spécifique
Logique de statut : vert / jaune / rouge
Lorsqu'une sonde interroge une cible, si cette dernière ne retourne pas le résultat attendu, alors elle peut ré-essayer après un instant. En fonction du résultats des différentes tentatives, la sonde déduit un statut de la cible :
- Vert : la cible a retourné le résultat attendu dès le premier essai
- Jaune : après un ou plusieurs échec la cible a fini par retourner le résultat attendu
- Rouge : toutes les tentatives ont échoué
Cette logique est importante car elle distingue :
- une indisponibilité franche (rouge)
- une dégradation partielle/intermittente (jaune)
Configuration de la levée d'incidents (point central)
Pour chaque statut anormal (jaune, rouge), on peut configurer la levée d'un incident et spécifier :
- sa priorité
- sa description
- ses tags
Pourquoi c'est utile
- un statut jaune peut déclencher un incident de priorité basse qui indique une dégradation
- un statut rouge peut déclencher un incident critique qui indique une indisponibilité totale
- chaque incident levé porte un contexte métier via description et tags
Bref : on passe d'une alerte technique brute à un incident opérationnel exploitable.
Consultation et suivi
Sur la vue de détail d'une sonde, on retrouve :
- la méthode HTTP
- le code attendu
- les headers & payload (si définis)
- l'historique des tentatives avec filtre temporel (dernière heure, dernier jour, 7 jours, 30 jours)
- le temps de réponse moyen, uptime, nombre de tentatives
- les incidents levés dans l'historique
- la configuration des statuts/incidents
Ça permet de relier rapidement et de façon bidirectionnelle (sonde -> incident et incident -> sonde) :
- Ce qui a été vérifié
- Ce qui a échoué
- Et quel incident a été levé
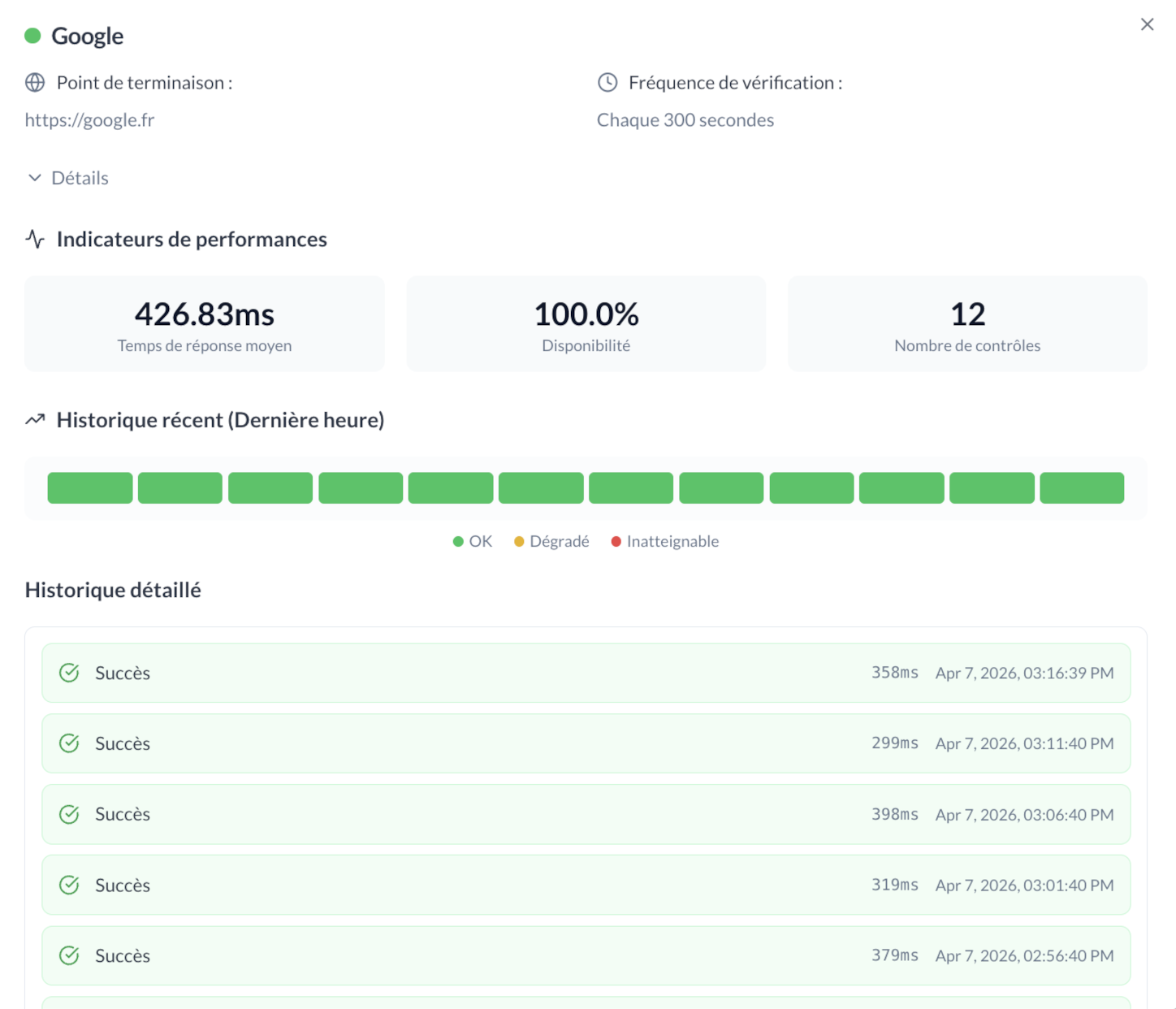 Exemple de détail d'une sonde
Exemple de détail d'une sonde
Vue d'ensemble dans le dashboard
Les sondes sont également visibles depuis le dashboard de supervision, qui offre une vue consolidée de l'état de vos services en un coup d'œil, sans avoir à naviguer dans chaque sonde individuellement.
Exemple simple de configuration
Cas : supervision d'un intranet authentifié.
- nom :
Intranet - status - endpoint :
https://intranet.example.com/api/status - méthode :
GET - expected status code :
200 - header :
Authorization: Bearer <token> - fréquence :
900secondes (15 min) - max tries :
3 - incident jaune : activé, priorité 3, description "Intranet partiellement dégradé"
- incident rouge : activé, priorité 2, description "Intranet indisponible"
Bonnes pratiques de paramétrage
- utiliser un nom de sonde explicite
- monitorer un endpoint représentatif de l'usage réel
- activer la levée d'incident en cas de statut jaune uniquement si vous avez un réel besoin de tracer ce cas (c'est relativement rare)
- taguer les incidents pour faciliter tri et corrélation
En résumé
Ce dispositif de sondes HTTP permet de :
- détecter les potentiels sites KO (intranet, sites web publics, API)
- aller au-delà d'un GET simple (verbes HTTP complets, headers, payload)
- transformer un statut en incident structuré
La vraie valeur est là : une supervision technique reliée nativement à une gestion d'incident actionnable.
Intéressé ? N'hésitez pas à essayer Astry gratuitement.